
Optimisation du Contexte et des Compétences de l'IA
Bloqué dans le 'Vibe Coding' ? Découvrez comment réduire jusqu'à 70% l'utilisation des tokens et améliorer la précision de l'IA dans les grandes bases de code avec Model Context Protocol.
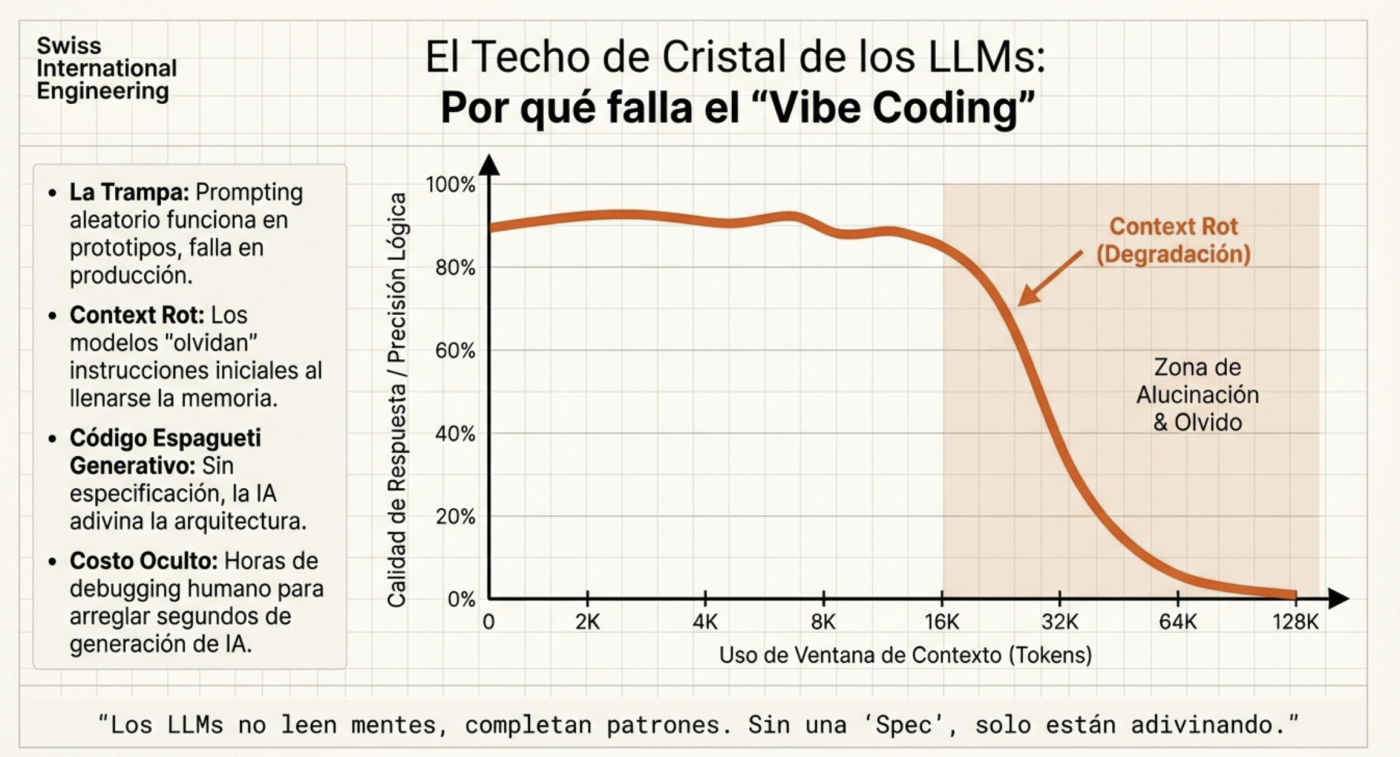
Le paysage du développement logiciel a considérablement changé. Il ne s’agit plus seulement d’écrire du code plus rapidement avec une autocomplétion intelligente ; nous entrons dans l’ère de l’orchestration d’agents. Cependant, de nombreux développeurs restent piégés dans ce que nous appelons le “Vibe Coding” : lancer des prompts aléatoires et espérer que l’IA devine l’intention.
Si vous souhaitez faire évoluer vos solutions et cesser de “brûler” des tokens inutilement, il est fondamental de comprendre que l’IA exige une structure et des outils spécifiques pour raisonner avec précision.
Le Fantôme dans la Machine : La “Pourriture du Contexte” et la Gestion des Tokens
L’un des plus grands défis du développement assisté par l’IA est la dégradation du contexte. Au fur et à mesure qu’une conversation s’allonge, le modèle a tendance à perdre le fil des décisions précédentes, ce qui génère des incohérences et des hallucinations. En moyenne, le contexte commence à perdre des “connexions” à partir d’environ 60%, c’est pourquoi il est idéal d’utiliser un outil qui permet de visualiser l’utilisation du contexte actuel (Claude et Kilocode permettent de le voir à l’écran, et Opencode dispose d’une extension pour faire de même). Il est donc préférable, par exemple, de faire la planification et, une fois celle-ci terminée, de la transférer dans un fichier Markdown pour pouvoir l’utiliser comme référence et enfin de nettoyer le contexte (démarrer une nouvelle session) afin de pouvoir commencer l’exécution en utilisant ce plan généré avec un contexte propre. C’est pourquoi il faut consacrer beaucoup de temps à l’élaboration d’un très bon plan. En fait, les dernières versions de Claude Code le font déjà automatiquement.
Pour lutter contre cela, la clé n’est pas de donner plus d’informations, mais des informations mieux structurées. C’est là que des outils comme le Model Context Protocol (MCP) et les systèmes de récupération sémantique font la différence.
Serena : Le “Microscope” pour votre Code
De nombreux développeurs commettent l’erreur de joindre des fichiers entiers au chat. Je l’ai aussi fait, en essayant de lui faire trouver “magiquement” le contenu dont il pourrait avoir besoin à un moment donné. Mais cela est non seulement coûteux, mais introduit également du “bruit” qui perturbe le modèle. Serena est une boîte à outils d’agents de code (disponible en tant que MCP) qui dote l’IA de capacités similaires à celles d’un IDE professionnel.
Comment Serena fonctionne-t-elle en pratique ?
Contrairement à un simple grep, à la lecture d’un fichier .ts complet ou même à rip-grep, qui est une grande amélioration par rapport au grep normal pour les développeurs, Serena utilise les intégrations du Language Server Protocol (LSP) pour permettre à l’agent de “naviguer” dans le code au niveau des symboles :
- Recherche Chirurgicale : Au lieu de lire 500 lignes, l’agent utilise
find_symbolpour extraire uniquement la définition d’une classe ou d’une fonction spécifique. - Cartographie des Relations : Avec
find_referencing_symbols, l’agent peut comprendre qui appelle une fonction avant de la modifier, évitant ainsi les effets secondaires indésirables. - Édition de Haute Précision : Elle utilise des outils tels que
insert_after_symboloureplace_symbol_content, ce qui garantit que les modifications respectent la syntaxe et la structure du langage sans réécrire des fichiers entiers.
Pourquoi est-ce si utile ?
- Économie de Tokens (jusqu’à 70%) : En n’envoyant que les fragments pertinents (snippets) au lieu de fichiers massifs, vous réduisez drastiquement la consommation de votre quota quotidien.
- Atténuation des Hallucinations : Moins de bruit dans le contexte signifie que le modèle a un “focus laser” sur la logique qui importe vraiment.
- Scalabilité : C’est la seule façon viable de travailler sur des monorepos ou de grandes bases de code où il est physiquement impossible de charger tout le contexte dans une seule fenêtre.
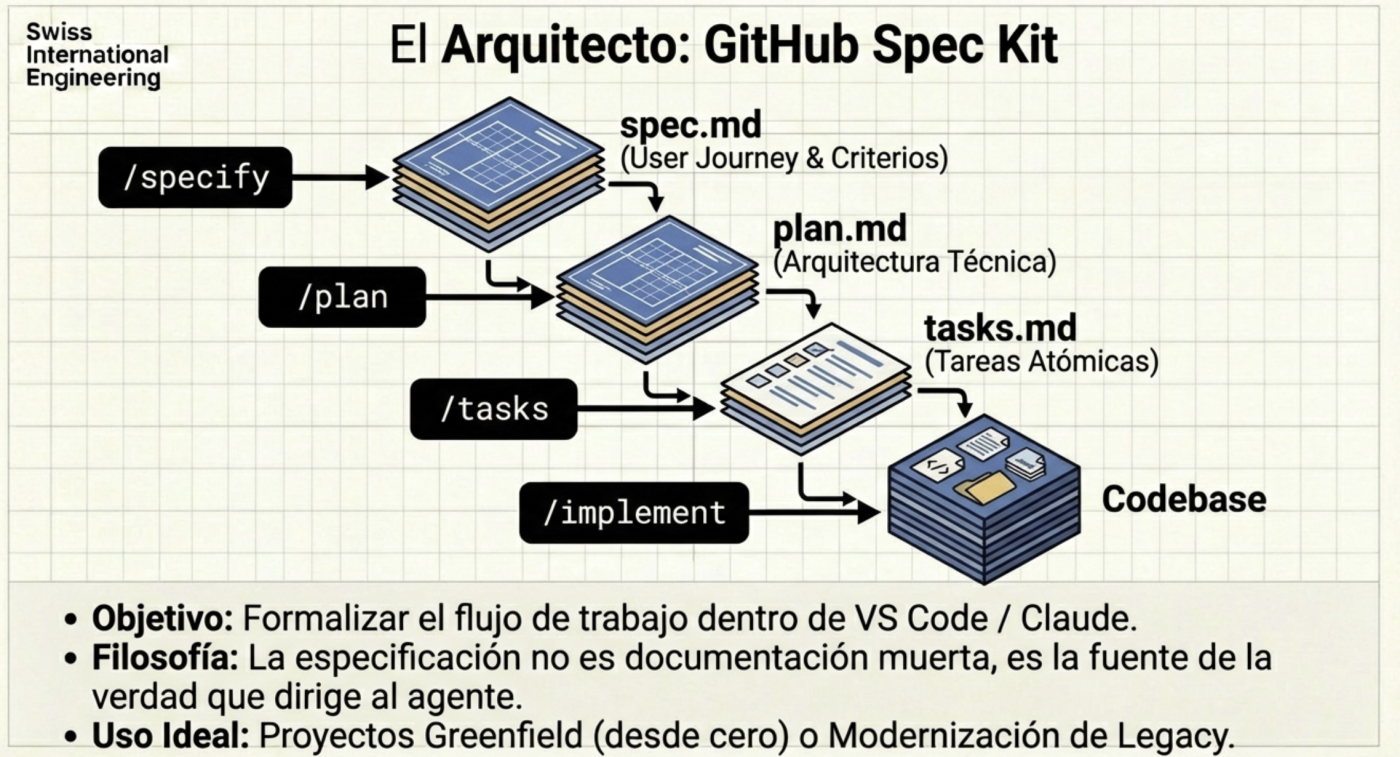
Développement Piloté par Spécification (SDD) : La fin de l’improvisation
Le développement basé sur des spécifications n’est pas nouveau, mais avec l’IA, il devient obligatoire. Il s’agit de régénérer une documentation d’ingénierie logicielle de base avec tous les processus et artefacts que vous avez probablement étudiés à l’université. La qualité du résultat d’un agent dépend directement de la rigueur de la spécification initiale.
Des frameworks comme GSD (Get Shit Done) ou le GitHub Spec Kit nous apprennent que la première étape ne doit pas être d’écrire du code, mais de définir le plan. Tous deux se chargent de vous poser toutes les questions, d’analyser l’existant, de délimiter les fonctionnalités, etc. Vous avez littéralement un assistant qui effectue le processus d’entretiens initiaux (uniquement avec vous dans ce cas) et génère les documents qui seront ensuite utilisés pour créer les fonctionnalités, corriger les erreurs, etc.
Le Workflow Idéal :
- Ingénierie du Contexte : Définir la stack, les règles de style et l’architecture de base. Dans le cas de GSD, cela crée un dossier planning avec une documentation très détaillée, comme un plan logiciel standard (Ingénierie Logicielle 101).
- Planification XML : Les agents traitent mieux les instructions lorsqu’elles sont structurées (ex. balises
<task>,<verify>,<done>). - Cycle de Vérification : Chaque tâche doit inclure une étape de validation automatique avant d’être considérée comme terminée.
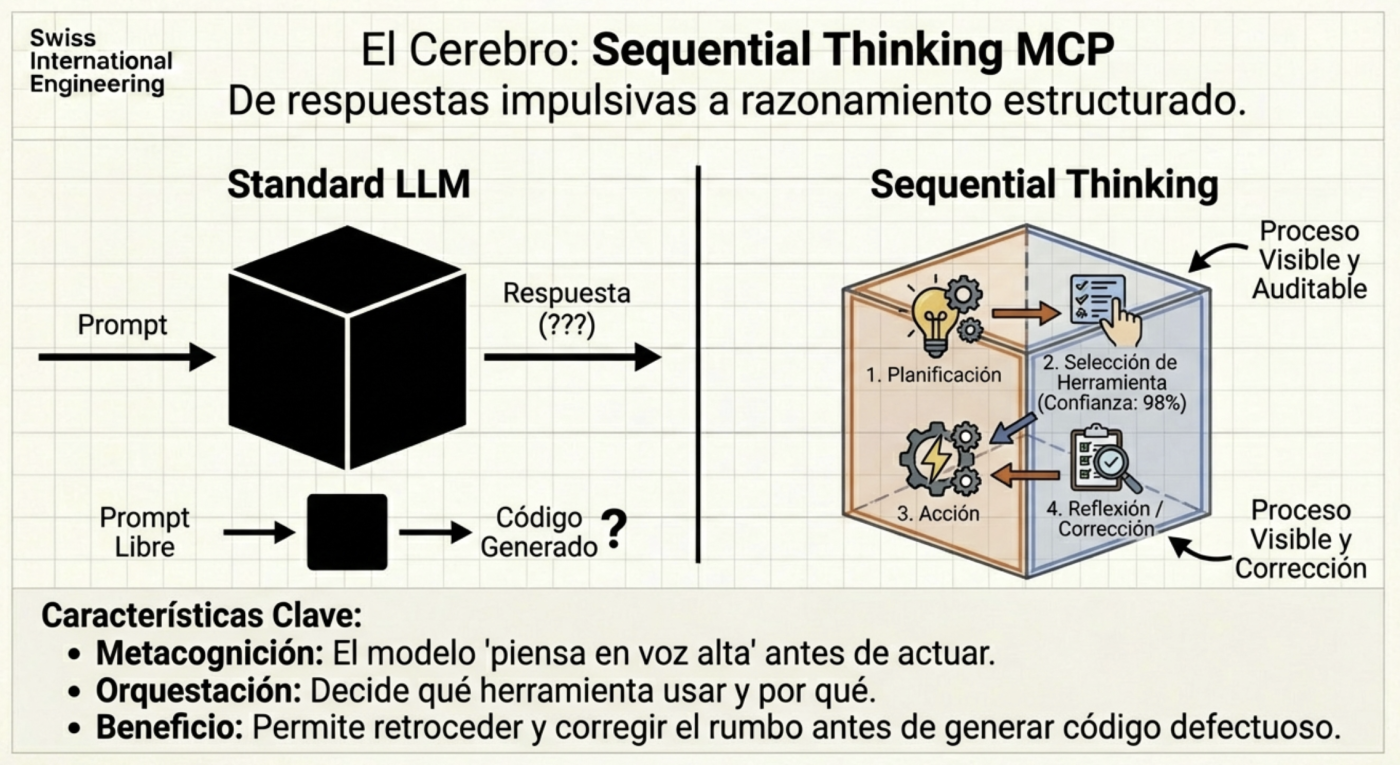
Pensée Séquentielle : Le Processus Cognitif
Parfois, le modèle tente de résoudre des problèmes complexes d’un seul coup. L’utilisation de serveurs MCP comme celui de Sequential Thinking permet à l’IA de “penser à voix haute” et de diviser le problème en étapes séquentielles. Cela transforme l’IA d’un outil génératif en un agent doté d’une capacité de raisonnement critique, capable d’admettre quand une voie n’est pas viable et d’essayer une alternative avant de vous livrer un résultat défaillant.
Utilisez des Skills, pas des MCP, pour les tâches déterministes
Le bénéfice majeur réside dans l’Économie Massive de Tokens (Efficacité de la “Progressive Disclosure”, ou Révélation Progressive). C’est le gain le plus tangible, tant sur le plan économique que sur celui de la performance.
- Le problème : Si vous placez toutes vos règles, guides de style et scripts dans le “System Prompt”, vous saturez la fenêtre de contexte immédiatement. Cela rend l’IA lente et coûteuse.
- La solution (Skills) : Les Skills fonctionnent selon le principe de la “Révélation Progressive”. L’IA ne charge en mémoire que le nom et la description du Skill. Ce n’est que lorsque vous lui demandez une tâche liée (ex: “Révise ce PR”) que l’IA charge les instructions lourdes de ce Skill spécifique.
- Résultat : Vous maintenez votre contexte propre et évitez la “pourriture du contexte” (context rot), ce qui réduit les coûts et empêche l’IA de s’embrouiller avec des instructions non pertinentes.
Déterminisme vs. Hallucination
Les Skills permettent d’exécuter des actions déterministes (prévisibles) plutôt que créatives.
- Exemple : Au lieu de demander à l’IA de “tenter de formater” un fichier (ce qui peut inventer des syntaxes), vous utilisez un Skill qui exécute un script réel (comme Prettier ou un linter) ou suit un template strict. Vous pouvez même inclure des templates dans le Skill, par exemple un modèle pour générer un nouvel endpoint REST qui suit toujours la même structure.
- Exemple : Un Skill pour ajouter des licences (license-header-adder) garantit que chaque nouveau fichier possède le copyright exact de votre entreprise, sans que vous ayez à le rappeler dans chaque prompt.
Standardisation de l’Équipe (L’ “Expert du Projet”)
Les Skills transforment des modèles génériques (comme Gemini ou Claude) en spécialistes de votre projet.
- Exemple : Vous pouvez créer un Skill global de “Code Review” qui oblige l’IA à vérifier des points spécifiques (sécurité, gestion des erreurs) avant d’approuver quoi que ce soit.
- Exemple : À la différence des “Custom Instructions” qui s’appliquent systématiquement, les Skills sont modulaires et portables. Vous pouvez partager un dossier
.github/skillsou.agent/skillsavec votre équipe, et tous les agents (Copilot, Claude Code, Antigravity) suivront automatiquement les mêmes standards.
Guide d’Installation et de Configuration de Serena MCP
Pour cesser de “brûler” des tokens et commencer à opérer avec une précision chirurgicale, vous devez intégrer Serena dans votre “Lien Neural” (votre environnement de développement). Voici les étapes exactes pour configurer ce MCP sur les clients les plus populaires.
0. Prérequis
Avant de commencer, assurez-vous d’avoir installé :
- Python (3.10+).
- Un client compatible avec MCP (Claude, Cursor, Open Code ou Windsurf).
1. Prérequis
La meilleure façon de l’utiliser est via uvx, cela permet de télécharger et d’exécuter automatiquement la dernière version :
Si vous utilisez Mac ou Linux, vous pouvez utiliser Homebrew :
brew install uvSi vous utilisez une autre plateforme et n’avez pas utilisé uv auparavant, je vous recommande de consulter sa documentation
2. Configuration par Client
Cursor / VS Code (Extensions MCP)
Je recommande de l’installer manuellement en ouvrant le fichier de configuration globale et en le collant dans la section MCPs :
{
"servers": {
"oraios/serena": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context",
"ide",
"--project",
"${workspaceFolder}"
]
}
},
"inputs": []
}Claude Code (Terminal)
Si vous utilisez déjà la CLI d’Anthropic, l’intégration est immédiate :
claude mcp add serena -- uvx --from git+https://github.com/oraios/serena serena start-mcp-server --context ide-assistant --project $(pwd)OpenCode / Gemini (Terminal)
{
"mcp": {
"serena": {
"type": "local",
"command": [
"uvx",
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context=ide",
"--project-from-cwd"
]
}
}
}
3. Vérification de la Synchronisation
Une fois configuré, redémarrez votre client et vérifiez si l’agent reconnaît ses nouvelles “compétences”. Lancez ce prompt sur un projet réel :
“Utilisez Serena pour rechercher la définition du symbole [NomDeVotreClasse] et dites-moi qui y fait référence dans le projet.”
Si vous constatez que l’agent utilise des outils comme find_symbol ou find_referencing_symbols au lieu de lire le fichier entier, vous êtes synchronisé.
4. Astuces
- Évitez le bruit : Vous n’avez pas besoin d’avoir 20 serveurs MCP actifs. Gardez Serena comme votre outil principal pour la navigation de code et n’activez les autres (comme Google Calendar ou Slack) que lorsque la tâche l’exige. Actuellement, je n’ai que 2 MCPs toujours actifs, Serena et SequentialThinking, le reste est passé en “Skills”.
- Chargement Paresseux (Lazy Loading) : N’oubliez pas que Serena excelle dans les grands projets. Si vous travaillez sur un projet de 3 fichiers, la différence sera minime, mais dans un monorepo, Serena est ce qui vous permettra de continuer à opérer lorsque d’autres n’auront plus de quota de tokens.
- Problèmes courants : Si Serena ne trouve pas un symbole, cela peut être un problème d’indexation du LSP. Ne forcez pas l’agent ; parfois un simple
lsoucatmanuel aide à réorienter le contexte.
Réflexion Finale
Pour utiliser l’IA, il faut agir en tant que leaders techniques, où notre responsabilité est de maintenir l’honnêteté technique. Nous devons savoir quand un agent a atteint sa limite et quand notre intervention manuelle est indispensable. Maîtriser la stack d’orchestration d’agents est ce qui séparera les programmeurs des ingénieurs logiciels dans les années à venir.
Avez-vous essayé d’utiliser un serveur MCP comme Serena pour “nettoyer” votre contexte, ou continuez-vous à faire confiance à l’IA pour comprendre vos “vibes” avec des fichiers de mille lignes ?