
Optimizando el Contexto y Skills en la IA
¿Atrapado en el "Vibe Coding"? Descubre cómo reducir hasta un 70% el uso de tokens y mejorar la precisión de la IA en codebases grandes con Model Context Protocol.
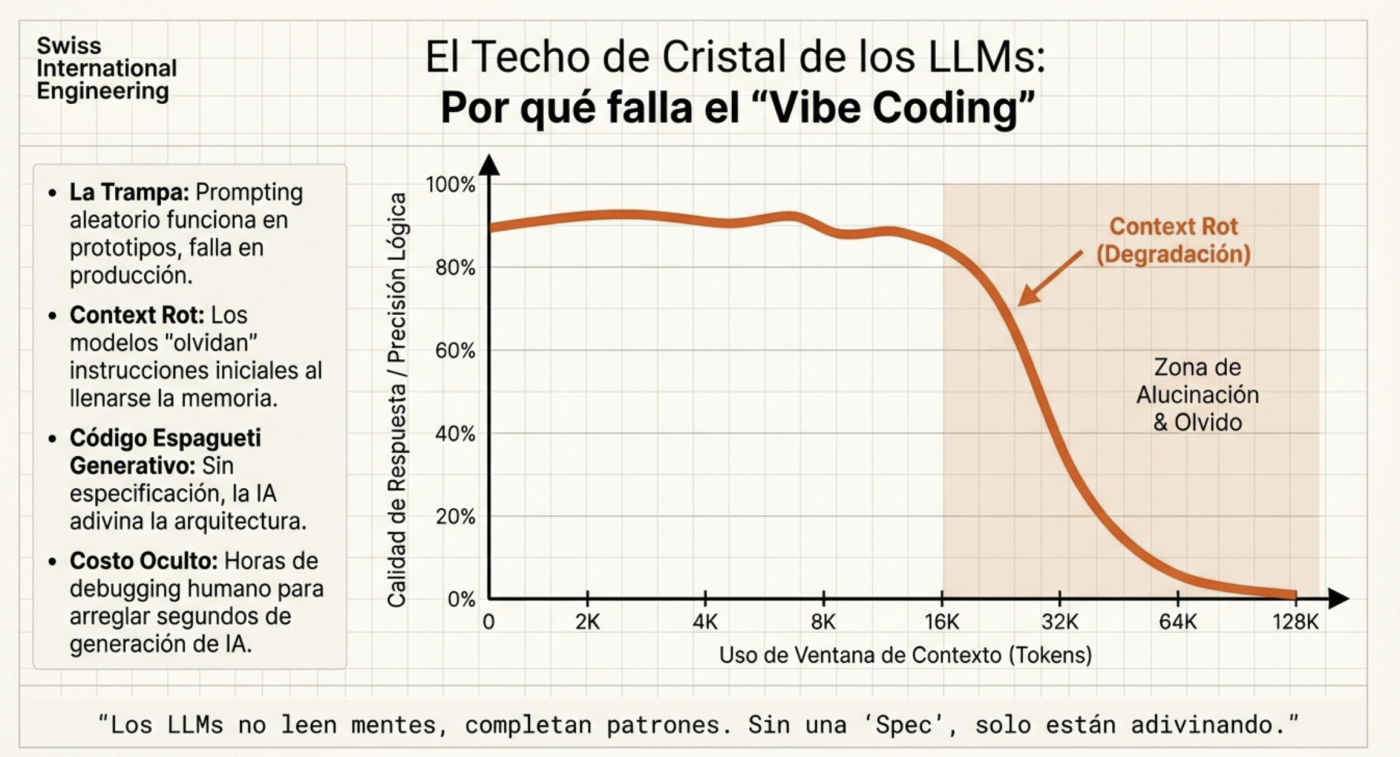
El panorama del desarrollo de software ha cambiado drásticamente. No se trata solo de escribir código más rápido con un autocompletado inteligente; estamos entrando en la era de la orquestación de agentes. Sin embargo, muchos desarrolladores siguen atrapados en lo que llamamos “Vibe Coding”: lanzar prompts al azar y esperar que la IA adivine la intención.
Si quieres escalar tus soluciones y dejar de “quemar” tokens innecesariamente, es fundamental entender que la IA requiere estructura y herramientas específicas para razonar con precisión.
El Fantasma en la Máquina: El “Context Rot” y la Gestión de Tokens
Uno de los mayores desafíos en el desarrollo asistido por IA es la degradación del contexto. A medida que una conversación se alarga, el modelo tiende a perder el hilo de las decisiones previas, lo que genera inconsistencias y alucinaciones. El promedio el contexto llega a perder “conexiones” es a partir de alrededor del 60%, por eso es ideal usar una herramienta que permita ver el uso del contexto actual (tanto Claude como Kilocode permiten verlo en pantalla, y Opencode tiene una extensión para hacer lo mismo). Por ello lo mejor es por ejemplo hacer la planificación y luego de terminarla, pasarlo a un archivo markdown para poder usarlo como referencia y finalmente limpiar el contexto (iniciar una nueva sesión) para poder comenzar la ejecución ya usando ese plan generado con un contexto limpio, por eso hay que dedicarle mucho tiempo a tener un muy buen plan. De hecho en las últimas versiones de Claude Code ya lo hace de forma automática.
Para combatir esto, la clave no es darle más información, sino información mejor estructurada. Aquí es donde herramientas como el Model Context Protocol (MCP) y sistemas de recuperación semántica marcan la diferencia.
Serena: El “Microscopio” para tu Código
Muchos desarrolladores cometen el error de adjuntar archivos enteros al chat. También lo he hecho, tratando de hacer que encuentre “mágicamente” el contenido que puede necesitar en algún momento. Pero esto no solo es costoso, sino que introduce “ruido” que confunde al modelo. Serena es un toolkit de agentes de código (disponible como MCP) que dota a la IA de capacidades similares a las de un IDE profesional.
¿Cómo funciona Serena en la práctica?
A diferencia de un simple grep, leer un archivo .ts completo o inclusive con rip-grep que es una gran mejora sobre el grep normal para desarrolladores, Serena utiliza integraciones de Language Server Protocol (LSP) para permitir que el agente “navegue” por el código a nivel de símbolos:
- Búsqueda Quirúrgica: En lugar de leer 500 líneas, el agente usa find_symbol para extraer solo la definición de una clase o función específica.
- Mapeo de Relaciones: Con find_referencing_symbols, el agente puede entender quién está llamando a una función antes de modificarla, evitando efectos secundarios no deseados.
- Edición de Alta Precisión: Utiliza herramientas como insert_after_symbol o replace_symbol_content, lo que garantiza que los cambios respeten la sintaxis y la estructura del lenguaje sin reescribir archivos enteros.
¿Por qué ayuda tanto?
- Ahorro de Tokens (hasta un 70%): Al enviar solo los fragmentos relevantes (snippets) en lugar de archivos masivos, reduces drásticamente el consumo de tu cuota diaria.
- Mitigación de Alucinaciones: Menos ruido en el contexto significa que el modelo tiene “foco láser” en la lógica que realmente importa.
- Escalabilidad: Es la única forma viable de trabajar en monorepos o codebases grandes donde es físicamente imposible cargar todo el contexto en una sola ventana.
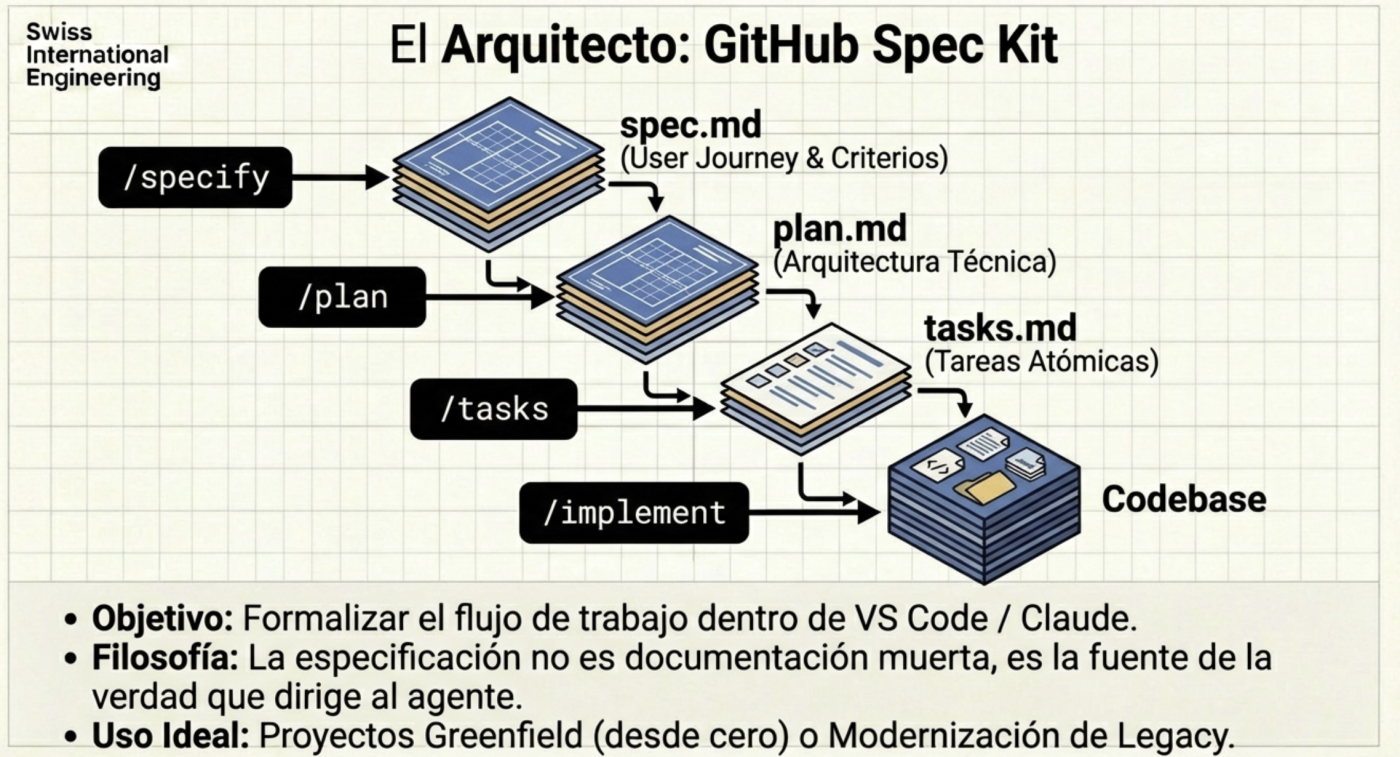
Spec-Driven Development (SDD): El fin de la improvisación
El desarrollo basado en especificaciones no es nuevo, pero con la IA se vuelve obligatorio, es volver a generar documentación básica de ingeniería de software con todos los procesos y artefactos que probablemente estudiaste en la universidad. La calidad del resultado de un agente depende directamente de la rigurosidad de la spec inicial.
Marcos de trabajo como GSD (Get Shit Done) o el GitHub Spec Kit nos enseñan que el primer paso no debe ser escribir código, sino definir el plan. Ambos se encargan de hacerte todas las preguntas, análisis de lo existente, acotamiento de funcionalidades, etc. Literalmente tienes a un asistente que hace el proceso de entrevistas iniciales (sólo a ti en este caso) y genera los documentos que luego se usarán para crear las funcionalidades, corrección de errores, etc.
El Workflow Ideal:
- Context Engineering: Definir el stack, las reglas de estilo y la arquitectura base, en el caso de GSD crea una carpeta planning con toda la documentación muy detallada, como si un plan de software estándar (Ingeniería de Software 101).
- Planificación XML: Los agentes procesan mejor las instrucciones cuando están estructuradas (ej. etiquetas <task>, <verify>, <done>).
- Ciclo de Verificación: Cada tarea debe incluir un paso de validación automática antes de considerarse terminada.
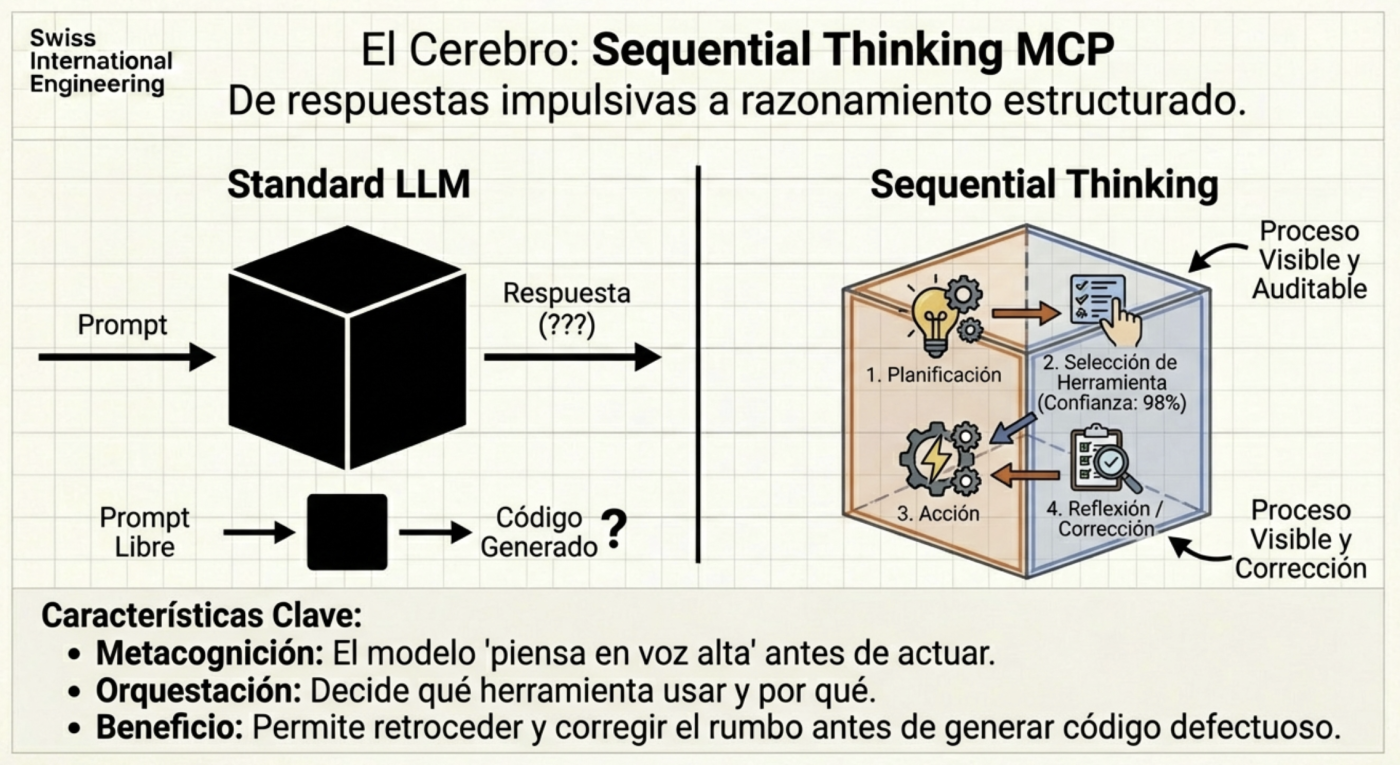
Sequential Thinking: El Proceso Cognitivo
A veces, el modelo intenta resolver problemas complejos de un solo golpe. El uso de servidores MCP como el de Sequential Thinking permite que la IA “piense en voz alta” y divida el problema en pasos secuenciales. Esto transforma a la IA de una herramienta generativa a un agente con capacidad de razonamiento crítico, capaz de admitir cuando una ruta no es viable y probar una alternativa antes de entregarte un resultado fallido.
Usa Skills, no MCPs para tareas determinísticas
El gran beneficio es el Ahorro Masivo de Tokens (Eficiencia de “Progressive Disclosure”, o Revelación Progresiva), eso es el beneficio más tangible es económico y de rendimiento.
- El problema: Si pones todas tus reglas, guías de estilo y scripts en el “System Prompt”, llenas la ventana de contexto inmediatamente. Esto hace que la IA sea lenta y costosa.
- La solución (Skills): Las Skills funcionan bajo el principio de “Revelación Progresiva”. La IA solo carga en su memoria el nombre y la descripción del Skill. Solo cuando tú le pides algo relacionado (ej. “Revisa este PR”), la IA carga las instrucciones pesadas de ese Skill específico.
- Resultado: Mantienes tu contexto limpio y evitas la “podredumbre del contexto” (context rot), lo que reduce costos y evita que la IA se confunda con instrucciones irrelevantes.
Determinismo vs. Alucinación
Las Skills permiten ejecutar acciones determinísticas (predecibles) en lugar de creativas.
- Ejemplo: En lugar de pedirle a la IA que “trate de formatear” un archivo (lo cual puede inventar sintaxis), usas un Skill que ejecuta un script real (como Prettier o un linter) o sigue una plantilla estricta. Inclusive puedes tener templates incluidos en el Skill, por ejemplo un template para generar un nuevo endpoint REST que siempre siga la misma estructura.
- Ejemplo: Un Skill para añadir licencias (license-header-adder) asegura que cada archivo nuevo tenga el copyright exacto de tu empresa, sin que tengas que recordárselo en cada prompt.
Estandarización del Equipo (El “Experto en Proyecto”)
Las Skills convierten a modelos genéricos (como Gemini o Claude) en especialistas de tu proyecto.
- Ejemplo: Puedes crear un Skill global de “Code Review” que obligue a la IA a verificar puntos específicos (seguridad, manejo de errores) antes de aprobar algo.
- Ejemplo: A diferencia de las “Custom Instructions” que se aplican siempre, las Skills son modulares y portátiles. Puedes compartir una carpeta .github/skills o .agent/skills con tu equipo, y todos los agentes (Copilot, Claude Code, Antigravity) seguirán los mismos estándares automáticamente
Guía de Instalación y Configuración de Serena MCP
Para dejar de quemar tokens y empezar a operar con precisión quirúrgica, necesitas integrar Serena en tu “Neural Link” (tu entorno de desarrollo). Aquí tienes los pasos exactos para configurar este MCP en los clientes más populares.
0. Requisitos Previos
Antes de empezar, asegúrate de tener instalado:
- Python (3.10+).
- Un cliente compatible con MCP (Claude, Cursor, Open Code o Windsurf).
1. Prerequisitos
La mejor forma es utilizarlo a través de uvx, esto permite que automáticamente se descargue y ejecute la última versión:
Si usas mac o linux puedes usar homebrew:
brew install uv
Si tienes otra plataforma y no has usado uv antes te recomiendo ver sus docs
2. Configuración por Cliente
Cursor / VS Code (Extensiones MCP)
Recomiendo instalarlo manualmente abriendo el archivo de configuración global y pegando en la sección de MCPs:
{
"servers": {
"oraios/serena": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context",
"ide",
"--project",
"${workspaceFolder}"
]
}
},
"inputs": []
}Claude Code (Terminal)
Si ya estás usando la CLI de Anthropic, la integración es inmediata:
claude mcp add serena -- uvx --from git+https://github.com/oraios/serena serena start-mcp-server --context ide-assistant --project $(pwd)OpenCode / Gemini (Terminal)
{
"mcp": {
"serena": {
"type": "local",
"command": [
"uvx",
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context=ide",
"--project-from-cwd"
]
}
}
}
3. Verificación de Sincronización
Una vez configurado, reinicia tu cliente y prueba si el agente reconoce sus nuevos “skills”. Lanza este prompt en un proyecto real:
“Usa Serena para buscar la definición del símbolo [NombreDeTuClase] y dime quién lo referencia en el proyecto.”
Si ves que el agente utiliza herramientas como find_symbol o find_referencing_symbols en lugar de leer el archivo completo, estás sincronizado.
4. Tips
- Evita el ruido: No necesitas tener activos 20 servidores MCP. Mantén Serena como tu herramienta principal para navegación de código y solo activa otros (como Google Calendar o Slack) cuando la tarea lo exija, en la actualidad yo sólo tengo 2 MCPs siempre activos, Serena y SequentialThinking, el resto se fue todo a Skills.
- Lazy Loading: Recuerda que Serena brilla en proyectos grandes. Si estás en un proyecto de 3 archivos, la diferencia será mínima, pero en un monorepo, Serena es lo que te permitirá seguir operando cuando otros se queden sin cuota de tokens.
- Problemas comunes: Si Serena no encuentra un símbolo, puede ser un tema de indexación del LSP. No fuerces al agente; a veces un simple
lsocatmanual ayuda a reorientar el contexto.
Reflexión Final
Para usar la IA, hay que actuar como líderes técnicos, donde nuestra responsabilidad es mantener la honestidad técnica. Debemos saber cuándo un agente ha llegado a su límite y cuándo nuestra intervención manual es indispensable. Dominar el stack de orquestación de agentes es lo que separará a los programadores de los ingenieros de software en los próximos años.
¿Has probado a usar un servidor MCP como Serena para “limpiar” tu contexto, o sigues confiando en que la IA entienda tus “vibes” con archivos de mil líneas?