
Otimizando o Contexto e Habilidades na IA
Preso no "Vibe Coding"? Descubra como reduzir em até 70% o uso de tokens e melhorar a precisão da IA em grandes bases de código com o Model Context Protocol.
O cenário do desenvolvimento de software mudou drasticamente. Não se trata apenas de escrever código mais rápido com um autocompletar inteligente; estamos entrando na era da orquestração de agentes. No entanto, muitos desenvolvedores ainda estão presos ao que chamamos de “Vibe Coding”: lançar prompts aleatórios e esperar que a IA adivinhe a intenção.
Se você quer escalar suas soluções e parar de “queimar” tokens desnecessariamente, é fundamental entender que a IA requer estrutura e ferramentas específicas para raciocinar com precisão.
O Fantasma na Máquina: O “Context Rot” e a Gestão de Tokens
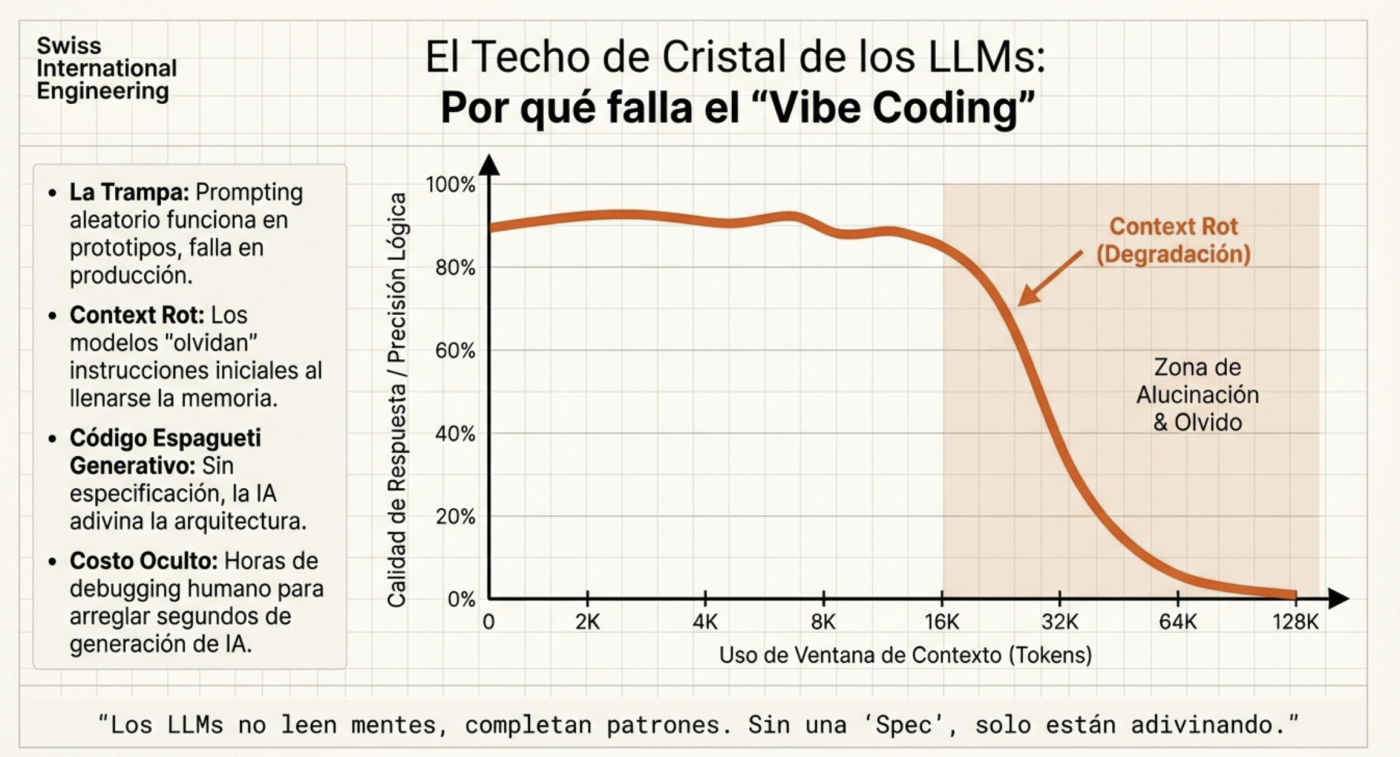
Um dos maiores desafios no desenvolvimento assistido por IA é a degradação do contexto. À medida que uma conversa se alonga, o modelo tende a perder o fio das decisões anteriores, o que gera inconsistências e alucinações. Em média, o contexto começa a perder “conexões” a partir de cerca de 60%, por isso é ideal usar uma ferramenta que permita ver o uso do contexto atual (tanto Claude quanto Kilocode permitem vê-lo na tela, e o Opencode tem uma extensão para fazer o mesmo). Por isso, o ideal é, por exemplo, fazer o planejamento e, após terminá-lo, passá-lo para um arquivo markdown para poder usá-lo como referência e, finalmente, limpar o contexto (iniciar uma nova sessão) para começar a execução usando esse plano gerado com um contexto limpo, por isso é preciso dedicar muito tempo a ter um plano muito bom. De fato, nas últimas versões do Claude Code, isso já é feito automaticamente.
Para combater isso, a chave não é dar mais informação, mas sim informação melhor estruturada. É aqui que ferramentas como o Model Context Protocol (MCP) e sistemas de recuperação semântica fazem a diferença.
Serena: O “Microscópio” para o seu Código
Muitos desenvolvedores cometem o erro de anexar arquivos inteiros ao chat. Eu também já fiz isso, tentando fazer com que ele encontrasse “magicamente” o conteúdo de que pode precisar em algum momento. Mas isso não só é custoso, como também introduz “ruído” que confunde o modelo. Serena é um toolkit de agentes de código (disponível como MCP) que equipa a IA com capacidades semelhantes às de um IDE profissional.
Como a Serena funciona na prática?
Diferente de um simples grep, ler um arquivo .ts completo ou inclusive com rip-grep, que é uma grande melhoria sobre o grep normal para desenvolvedores, a Serena utiliza integrações do Language Server Protocol (LSP) para permitir que o agente “navegue” pelo código em nível de símbolos:
- Busca Cirúrgica: Em vez de ler 500 linhas, o agente usa
find_symbolpara extrair apenas a definição de uma classe ou função específica. - Mapeamento de Relacionamentos: Com
find_referencing_symbols, o agente pode entender quem está chamando uma função antes de modificá-la, evitando efeitos colaterais indesejados. - Edição de Alta Precisão: Utiliza ferramentas como
insert_after_symboloureplace_symbol_content, o que garante que as alterações respeitem a sintaxe e a estrutura da linguagem sem reescrever arquivos inteiros.
Por que ajuda tanto?
- Economia de Tokens (até 70%): Ao enviar apenas os fragmentos relevantes (snippets) em vez de arquivos massivos, você reduz drasticamente o consumo da sua cota diária.
- Mitigação de Alucinações: Menos ruído no contexto significa que o modelo tem “foco a laser” na lógica que realmente importa.
- Escalabilidade: É a única forma viável de trabalhar em monorepos ou grandes bases de código onde é fisicamente impossível carregar todo o contexto em uma única janela.
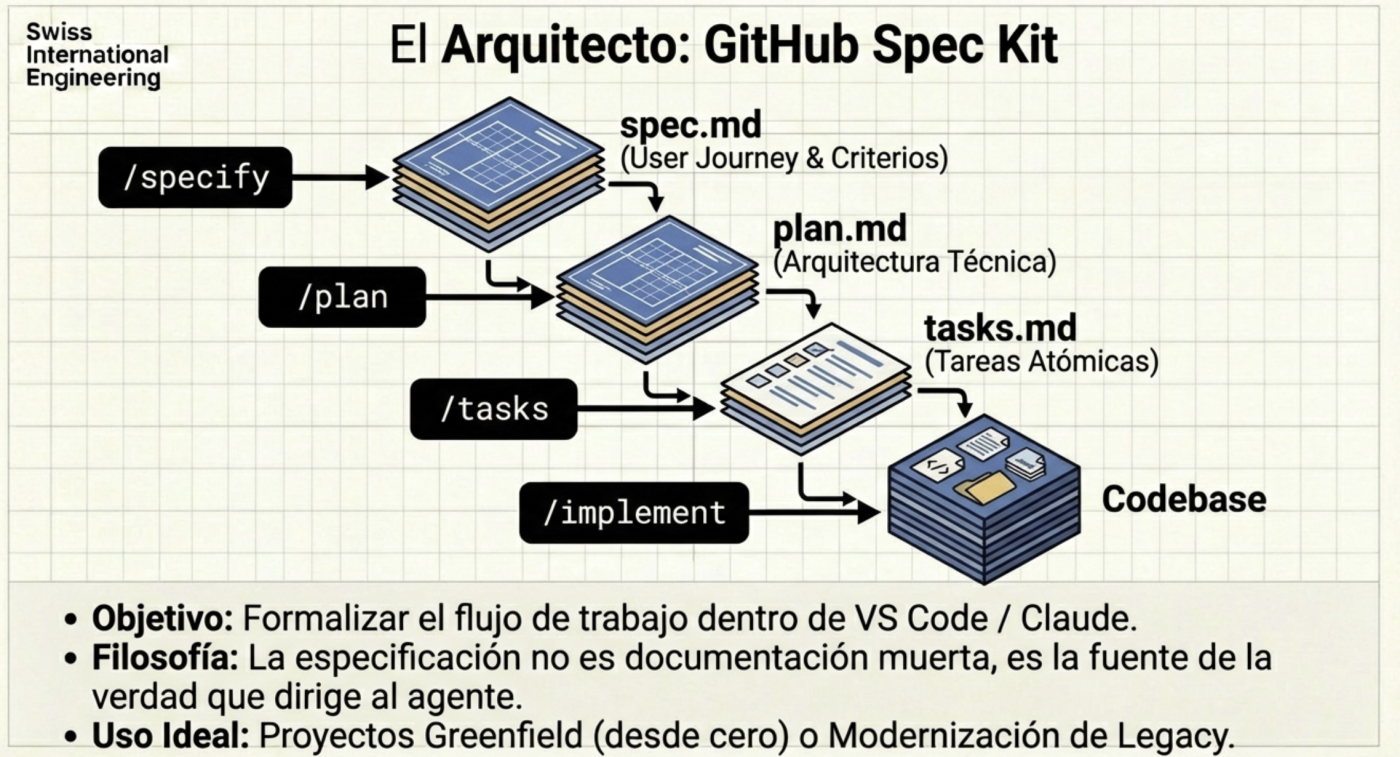
Spec-Driven Development (SDD): O fim da improvisação
O desenvolvimento baseado em especificações não é novo, mas com a IA se torna obrigatório, é voltar a gerar documentação básica de engenharia de software com todos os processos e artefatos que você provavelmente estudou na universidade. A qualidade do resultado de um agente depende diretamente da rigidez da especificação inicial.
Frameworks como GSD (Get Shit Done) ou o GitHub Spec Kit nos ensinam que o primeiro passo não deve ser escrever código, mas sim definir o plano. Ambos se encarregam de fazer todas as perguntas, análise do existente, delimitação de funcionalidades, etc. Literalmente, você tem um assistente que faz o processo de entrevistas iniciais (apenas com você neste caso) e gera os documentos que serão usados posteriormente para criar as funcionalidades, correção de erros, etc.
O Workflow Ideal:
- Context Engineering: Definir o stack, as regras de estilo e a arquitetura base, no caso do GSD cria uma pasta
planningcom toda a documentação muito detalhada, como se fosse um plano de software padrão (Engenharia de Software 101). - Planejamento XML: Os agentes processam melhor as instruções quando estão estruturadas (ex. tags
<task>,<verify>,<done>). - Ciclo de Verificação: Cada tarefa deve incluir uma etapa de validação automática antes de ser considerada terminada.
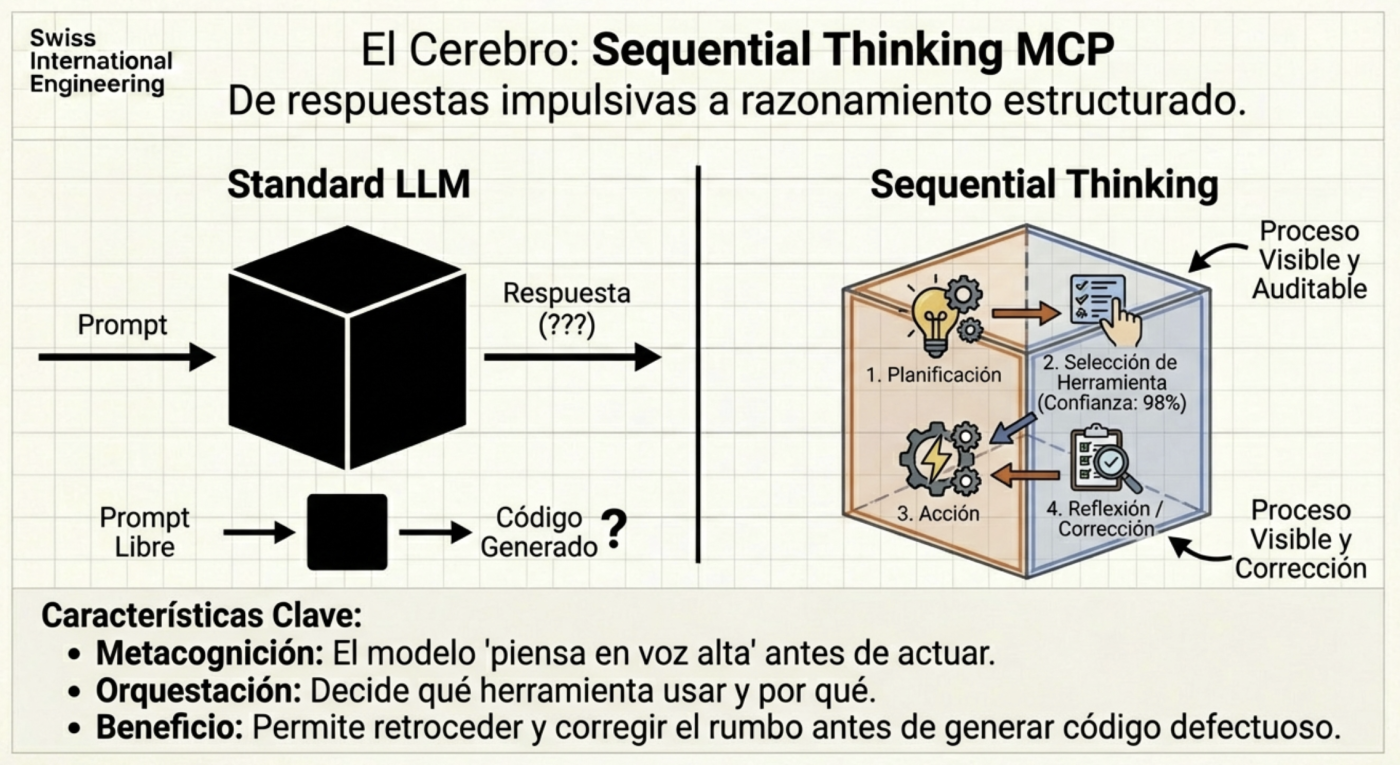
Sequential Thinking: O Processo Cognitivo
Às vezes, o modelo tenta resolver problemas complexos de uma só vez. O uso de servidores MCP como o do Sequential Thinking permite que a IA “pense em voz alta” e divida o problema em etapas sequenciais. Isso transforma a IA de uma ferramenta generativa em um agente com capacidade de raciocínio crítico, capaz de admitir quando um caminho não é viável e tentar uma alternativa antes de entregar um resultado falho.
Use Skills, não MCPs para tarefas determinísticas
O grande benefício é a Economia Massiva de Tokens (Eficiência de “Progressive Disclosure”, ou Revelação Progressiva); este é o ganho mais tangível em termos econômicos e de performance.
- O problema: Se colocar todas as suas regras, guias de estilo e scripts no “System Prompt”, a janela de contexto será preenchida imediatamente. Isso torna a IA lenta e cara.
- A solução (Skills): As Skills funcionam sob o princípio de “Revelação Progressiva”. A IA carrega na memória apenas o nome e a descrição da Skill. Somente quando você solicita algo relacionado (ex: “Revise este PR”), a IA carrega as instruções densas dessa Skill específica.
- Resultado: Você mantém seu contexto limpo e evita a “deterioração do contexto” (context rot), o que reduz custos e impede que a IA se confunda com instruções irrelevantes.
Determinismo vs. Alucinação
As Skills permitem executar ações determinísticas (previsíveis) em vez de criativas.
- Exemplo: Em vez de pedir à IA que “tente formatar” um arquivo (o que pode gerar sintaxes inventadas), você utiliza uma Skill que executa um script real (como Prettier ou um linter) ou segue um template rigoroso. Inclusive, pode ter templates embutidos na Skill, por exemplo, um padrão para gerar um novo endpoint REST que siga sempre a mesma estrutura.
- Exemplo: Uma Skill para adicionar licenças (license-header-adder) garante que cada novo arquivo tenha o copyright exato da sua empresa, sem que você precise lembrá-la disso em cada prompt.
Padronização da Equipe (O “Especialista do Projeto”)
As Skills transformam modelos genéricos (como Gemini ou Claude) em especialistas do seu projeto.
- Exemplo: Você pode criar uma Skill global de “Code Review” que obrigue a IA a verificar pontos específicos (segurança, tratamento de erros) antes de aprovar qualquer alteração.
- Exemplo: Diferente das “Custom Instructions”, que são aplicadas universalmente, as Skills são modulares e portáteis. Você pode compartilhar uma pasta
.github/skillsou.agent/skillscom seu time, e todos os agentes (Copilot, Claude Code, Antigravity) seguirão os mesmos padrões automaticamente.
Guia de Instalação e Configuração do Serena MCP
Para parar de queimar tokens e começar a operar com precisão cirúrgica, você precisa integrar Serena no seu “Neural Link” (seu ambiente de desenvolvimento). Aqui estão os passos exatos para configurar este MCP nos clientes mais populares.
0. Pré-requisitos
Antes de começar, certifique-se de ter instalado:
- Python (3.10+).
- Um cliente compatível com MCP (Claude, Cursor, Open Code ou Windsurf).
1. Pré-requisitos
A melhor forma é utilizá-lo através do uvx; isso permite que a última versão seja automaticamente baixada e executada:
Se você usa mac ou linux, pode usar homebrew:
brew install uvSe você tem outra plataforma e não usou uv antes, recomendo ver a documentação.
2. Configuração por Cliente
Cursor / VS Code (Extensões MCP)
Recomendo instalá-lo manualmente, abrindo o arquivo de configuração global e colando na seção de MCPs:
{
"servers": {
"oraios/serena": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context",
"ide",
"--project",
"${workspaceFolder}"
]
}
},
"inputs": []
}Claude Code (Terminal)
Se você já está usando a CLI da Anthropic, a integração é imediata:
claude mcp add serena -- uvx --from git+https://github.com/oraios/serena serena start-mcp-server --context ide-assistant --project $(pwd)OpenCode / Gemini (Terminal)
{
"mcp": {
"serena": {
"type": "local",
"command": [
"uvx",
"--from",
"git+https://github.com/oraios/serena",
"serena",
"start-mcp-server",
"--context=ide",
"--project-from-cwd"
]
}
}
}3. Verificação de Sincronização
Uma vez configurado, reinicie seu cliente e teste se o agente reconhece suas novas “habilidades”. Lance este prompt em um projeto real:
“Use Serena para buscar a definição do símbolo
[NomeDaSuaClasse]e me diga quem o referencia no projeto.”
Se você vir que o agente utiliza ferramentas como find_symbol ou find_referencing_symbols em vez de ler o arquivo completo, você está sincronizado.
4. Dicas
- Evite o ruído: Você não precisa ter 20 servidores MCP ativos. Mantenha Serena como sua ferramenta principal para navegação de código e ative outros (como Google Calendar ou Slack) apenas quando a tarefa exigir; atualmente, eu só tenho 2 MCPs sempre ativos, Serena e SequentialThinking, o resto foi tudo para Skills.
- Lazy Loading: Lembre-se que Serena se destaca em projetos grandes. Se você está em um projeto de 3 arquivos, a diferença será mínima, mas em um monorepo, Serena é o que permitirá que você continue operando quando outros ficarem sem cota de tokens.
- Problemas comuns: Se a Serena não encontrar um símbolo, pode ser uma questão de indexação do LSP. Não force o agente; às vezes um simples
lsoucatmanual ajuda a reorientar o contexto.
Reflexão Final
Para usar a IA, é preciso agir como líderes técnicos, onde nossa responsabilidade é manter a honestidade técnica. Devemos saber quando um agente atingiu seu limite e quando nossa intervenção manual é indispensável. Dominar o stack de orquestração de agentes é o que separará os programadores dos engenheiros de software nos próximos anos.
Você já experimentou usar um servidor MCP como o Serena para “limpar” seu contexto, ou ainda confia que a IA entenderá suas “vibes” com arquivos de mil linhas?